
Docker Compose 部署 Prometheus、Grafana:实现服务器、Web 应用的监控与告警

- Published on
- /9 mins read/---
技术栈简介
Prometheus
Prometheus 是一个开源的系统监控和告警工具。它通过拉取(Pull)模式从目标实例收集指标数据,并支持强大的查询语言 PromQL,用于分析和告警。Prometheus 的核心组件包括:
- Prometheus Server:负责数据采集和存储。
- Exporters:用于从各种系统和服务中暴露指标数据。
- Alertmanager:负责处理告警通知。
Grafana
Grafana 是一个开源的数据可视化工具,支持多种数据源(如 Prometheus、InfluxDB 等)。它可以将监控数据以图表的形式展示,帮助用户更直观地理解系统状态。Grafana 的主要功能包括:
- 创建动态仪表盘。
- 支持多种数据源。
- 提供丰富的可视化插件。
Alertmanager
Alertmanager 是 Prometheus 的告警管理组件,负责处理 Prometheus 发送的告警,并根据配置的路由规则发送通知(如邮件、Slack 等)。Alertmanager 的核心功能包括:
- 告警分组和去重。
- 支持多种通知渠道。
- 提供静默和抑制功能。
Node Exporter
Node Exporter 用于收集服务器主机的资源使用情况,如 CPU、内存、磁盘等。它通过暴露 HTTP 接口,将系统指标提供给 Prometheus 采集。
Blackbox Exporter
Blackbox Exporter 用于监控外部服务的可用性,如 HTTP/HTTPS、TCP、ICMP 等。它通过探针机制,定期检查目标服务的健康状态。
实现目标
监控服务器主机:通过 node-exporter 收集 CPU、内存、磁盘等指标。
监控 Web 应用:通过 blackbox_exporter 监控 Web 应用的 HTTP/HTTPS 可用性。
可视化监控数据:使用 Grafana 创建仪表盘,展示服务器、Web 应用的监控数据。
告警通知:通过 Alertmanager 配置告警规则,当服务器、Web 应用出现异常时,自动发送邮件通知。
部署步骤
创建项目目录
mkdir prometheus-grafana && cd prometheus-grafana编写 docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./alert.rules.yml:/etc/prometheus/alert.rules.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-lifecycle'
ports:
- '9090:9090'
restart: unless-stopped
networks:
- monitoring
grafana:
image: grafana/grafana:latest
container_name: grafana
volumes:
- grafana-data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
ports:
- '3000:3000'
restart: unless-stopped
networks:
- monitoring
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
- ./email.tmpl:/etc/alertmanager/email.tmpl
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
ports:
- '9093:9093'
restart: unless-stopped
networks:
- monitoring
node_exporter:
image: prom/node-exporter:latest
container_name: node_exporter
ports:
- '9100:9100'
restart: unless-stopped
networks:
- monitoring
blackbox_exporter:
image: prom/blackbox-exporter:latest
container_name: blackbox_exporter
ports:
- '9115:9115'
restart: unless-stopped
networks:
- monitoring
networks:
monitoring:
volumes:
grafana-data:配置 Prometheus
创建 prometheus.yml 文件,配置监控目标和告警规则文件:
global:
scrape_interval: 15s
rule_files:
- 'alert.rules.yml'
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['你的A服务器ip:9100', '你的B服务器ip:9100']
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- image.me.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox_exporter:9115
- source_labels: [__param_target]
regex: 'image.me.com'
target_label: webapp
replacement: '简单图床'
alerting:
alertmanagers:
- static_configs:
- targets: ['你的服务器ip:9093']NOTE
如果你的 web 应用没有域名,可以将域名替换成实际应用的 ip+port
配置告警规则
在 alert.rules.yml 中添加 Web 应用的告警规则:
groups:
- name: node_alerts
rules:
- alert: HighCPUUsage
expr: avg(rate(node_cpu_seconds_total{mode!="idle"}[2m])) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: 'High CPU Usage'
description: 'CPU 使用率超过 80% 持续 2 分钟'
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: 'High Memory Usage'
description: '内存使用率超过 80% 持续 2 分钟'
- alert: WebServiceDown
expr: probe_success == 0
for: 30s
labels:
severity: critical
annotations:
summary: 'Web Service Down'
description: 'Web 服务不可用'
- alert: InstanceDown
expr: up==0 # up 指标为 0 表示实例宕机
for: 30s
labels:
severity: critical
annotations:
summary: 'Instance {{ $labels.instance }} is down'
description: '{{ $labels.instance }}已宕机 '配置 Alertmanager
创建模板文件
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: <b>Prometheus Alertmanager</b> <br>
告警状态:
<span style="color:{{ if eq .Status "firing" }}red{{ else }}green{{ end }};">
{{ if eq .Status "firing" }}🔥 触发 {{ else }}✅ 恢复 {{ end }}
</span> <br>
告警级别: <b>{{ .Labels.severity }} 级</b> <br>
告警类型: <b>{{ .Labels.alertname }}</b> <br>
故障主机: <b>{{ .Labels.instance }}</b> <br>
告警主题: <b>{{ .Annotations.summary }}</b> <br>
告警详情: {{ .Annotations.description }} <br>
触发时间:<b>{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</b> <br>
{{ if and (ne .EndsAt.Unix 0) (ne .EndsAt.Year 1) }}
恢复时间:<b>{{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</b> <br>
{{ end }}
=========end==========<br>
{{ end }}
{{ end }}CAUTION
时间格式化按照示例里的格式写,否则格式化结果不正确
获取邮箱授权码
- 打开您的Google账户。
- 点击浏览器右上角的个人头像。
- 选择
管理 Google 账号。 - 在左侧导航栏中,找到
安全性。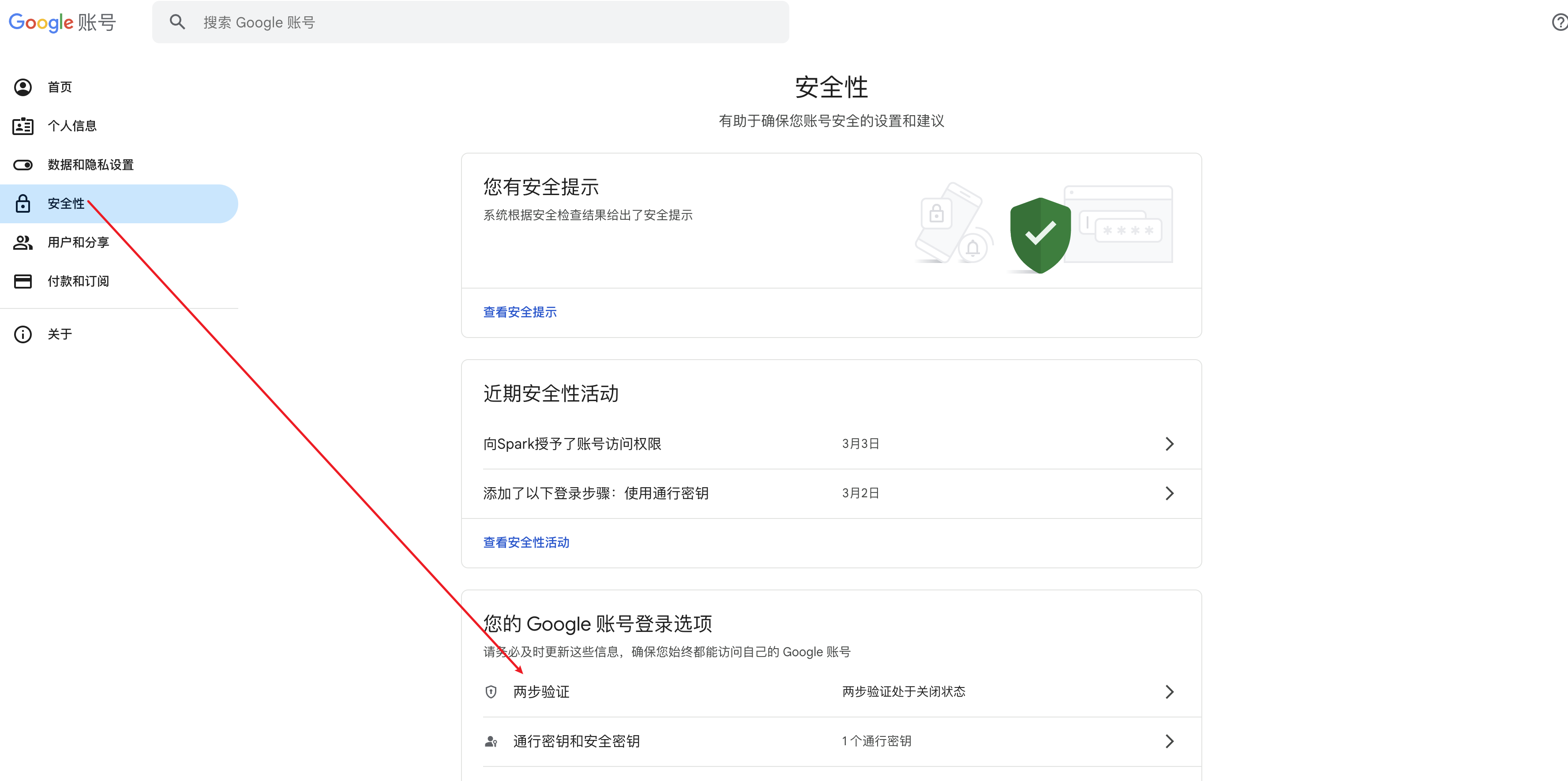
- 设置双重验证。
- 在
安全性页面中找到两步验证。 - 按照屏幕提示输入密码开启双重验证。
- 在
- 点击 此链接 创建应用并获取授权码。
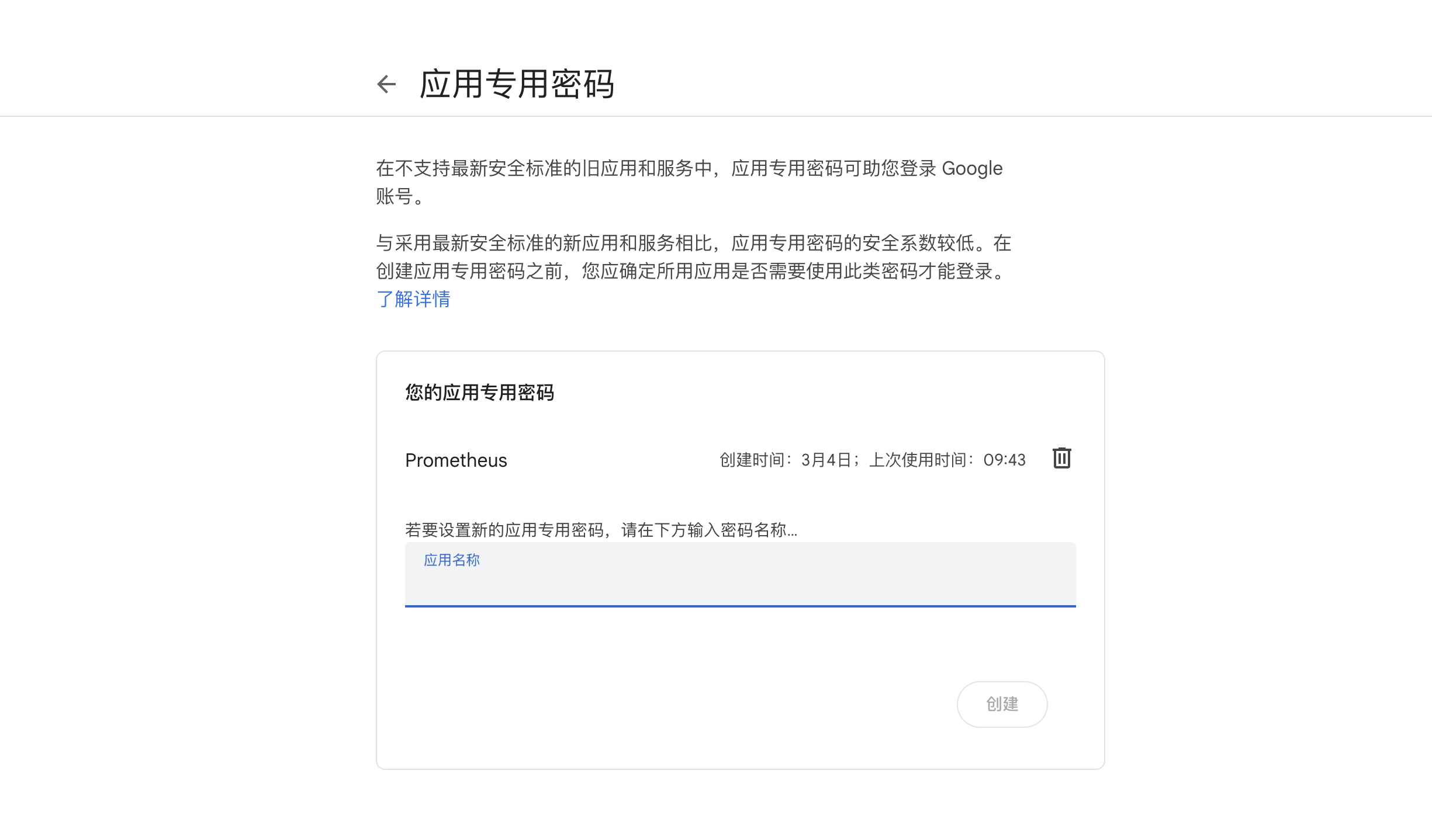
创建 alertmanager.yml 配置文件
global:
resolve_timeout: 5m
smtp_from: '邮件发送地址'
smtp_smarthost: 'smtp.gmail.com:465'
smtp_auth_username: '邮件发送地址'
smtp_auth_password: '授权码'
smtp_require_tls: false
templates:
- '/etc/alertmanager/email.tmpl'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '邮件接收地址'
html: '{{ template "email.to.html" . }}'
headers: { Subject: 'Prometheus [Warning] 告警邮件' }
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']- smtp_smarthost:用于发送邮件的邮箱 SMTP 服务器地址+端口。(比如谷歌邮箱的是:smtp.gmail.com:465)
- smtp_auth_username:你自己的邮箱地址。
- headers:邮件标题。
- ⚠️ smtp_auth_password:不是邮箱的密码,而是发送邮箱的授权码。
- ⚠️ templates:声明邮件的模板路径,需要与
docker-compose.yml文件中alertmanager容器挂载的路径一致。 - html:Go 语言的
html/template模板语法,双引号里的内容email.to.html即为模板名称,要和模板文件中定义的一致。
启动服务
docker-compose up -d配置 Grafana 仪表盘
- 访问 Grafana:
http://localhost:3000,默认用户名和密码为admin/admin。
- 添加 Prometheus 数据源:

- 导入仪表盘:
- Node Exporter Dashboard 20240520 通用JOB分组版(ID: 16098):用于监控服务器主机。
- Blackbox Exporter (HTTP prober)(ID: 13659):用于监控 Web 应用的可用性。
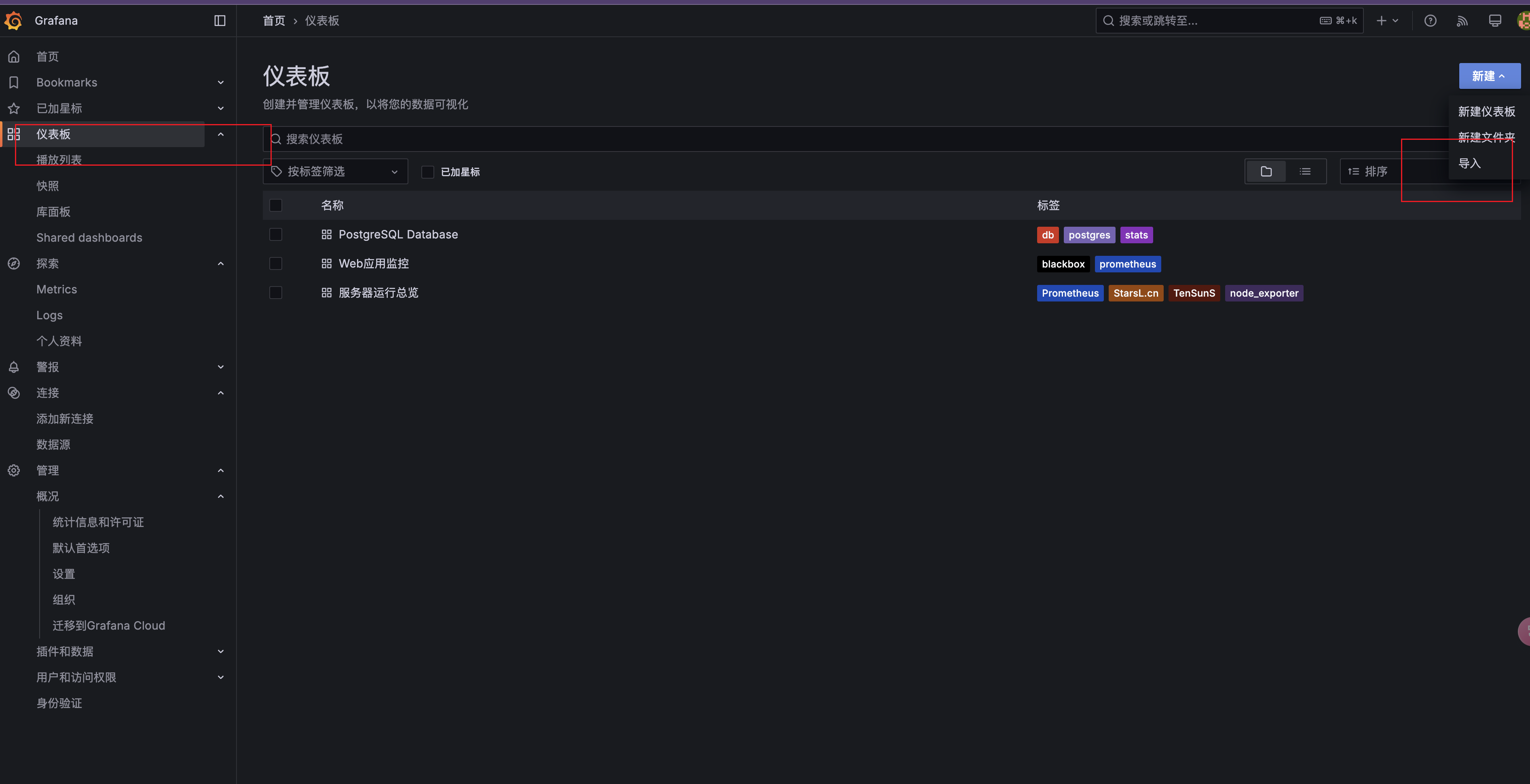

验证监控
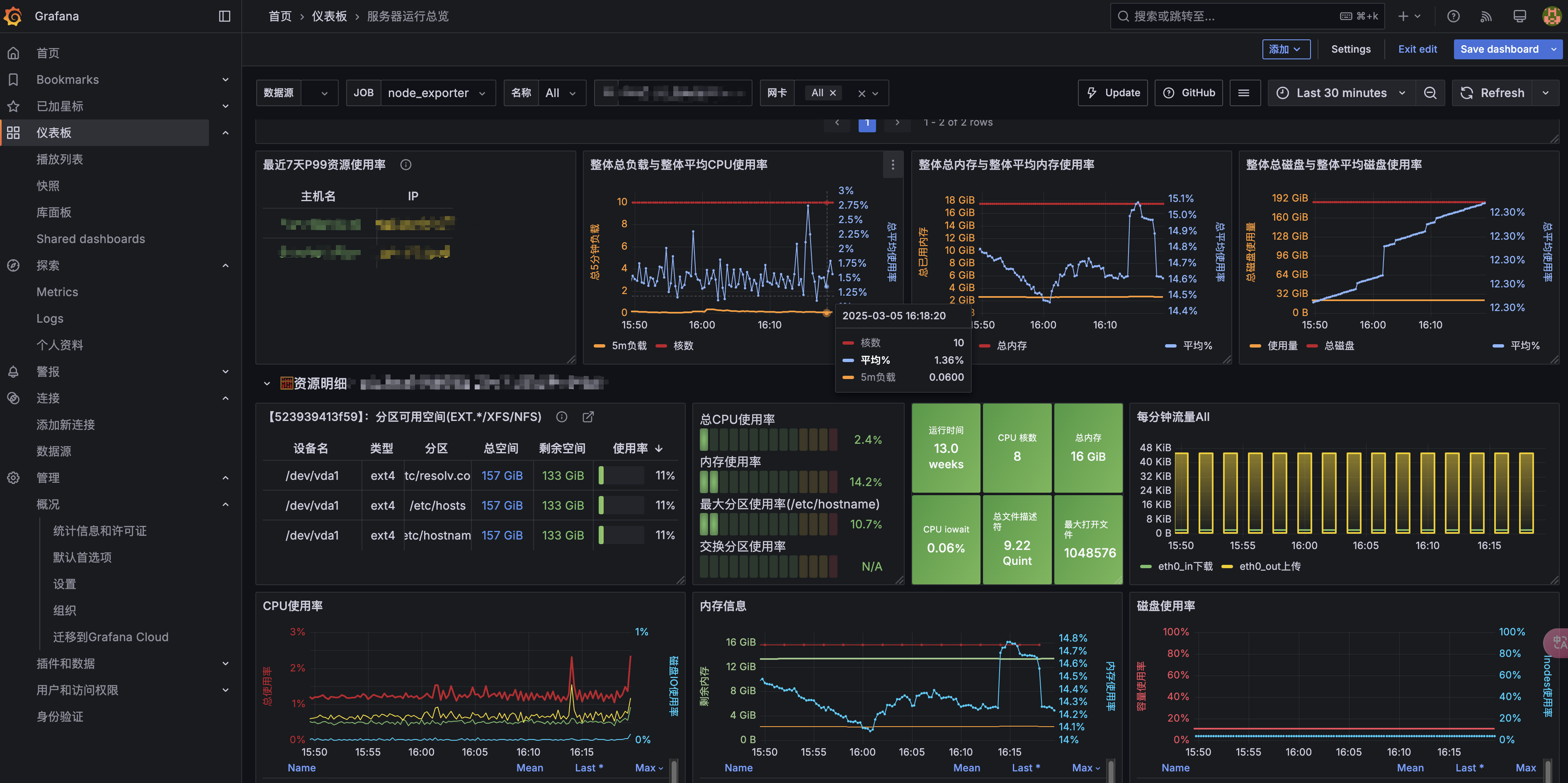
服务器监控:访问 Grafana,查看 Node Exporter 仪表盘,确认服务器指标正常。
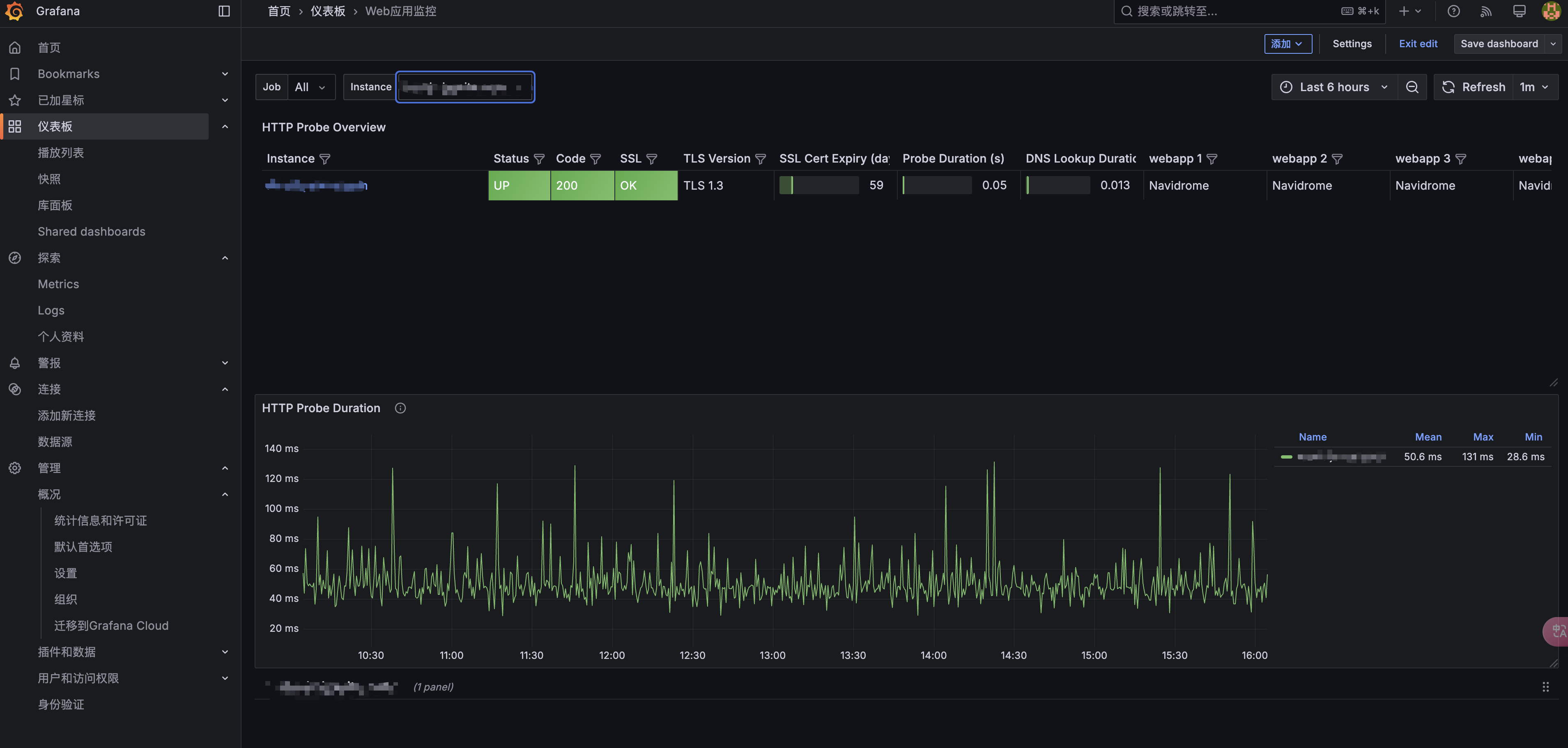
Web 应用监控:访问 Grafana,查看 Blackbox Exporter 仪表盘,确认 Web 应用的可用性。
告警通知
停止 web 服务,验证是否收到告警邮件。
docker stop web服务id浏览器访问 Prometheus 管理界面可以看到如下信息:
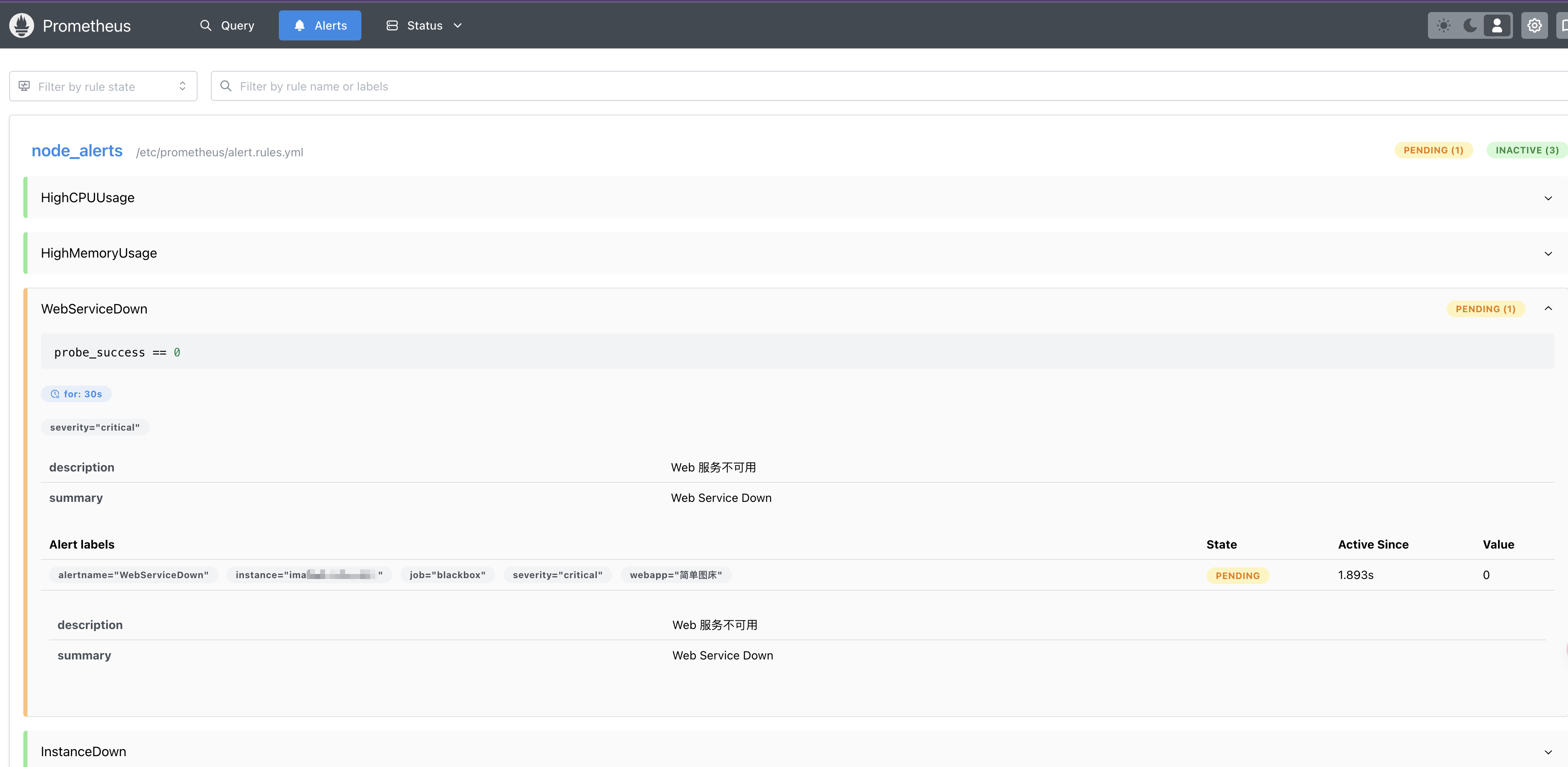
- 绿色:表示正常。
- 黄色:PENDING 表示告警还没有发送到 Alertmanager ,因为
rules里面配置了for: 30s。 30秒后状态由 PENDING 变为 FIRING ,此时 Prometheus 才将告警发给 Alertmanager ,同时打开 Alertmanager 界面可以看到有一条新的告警产生。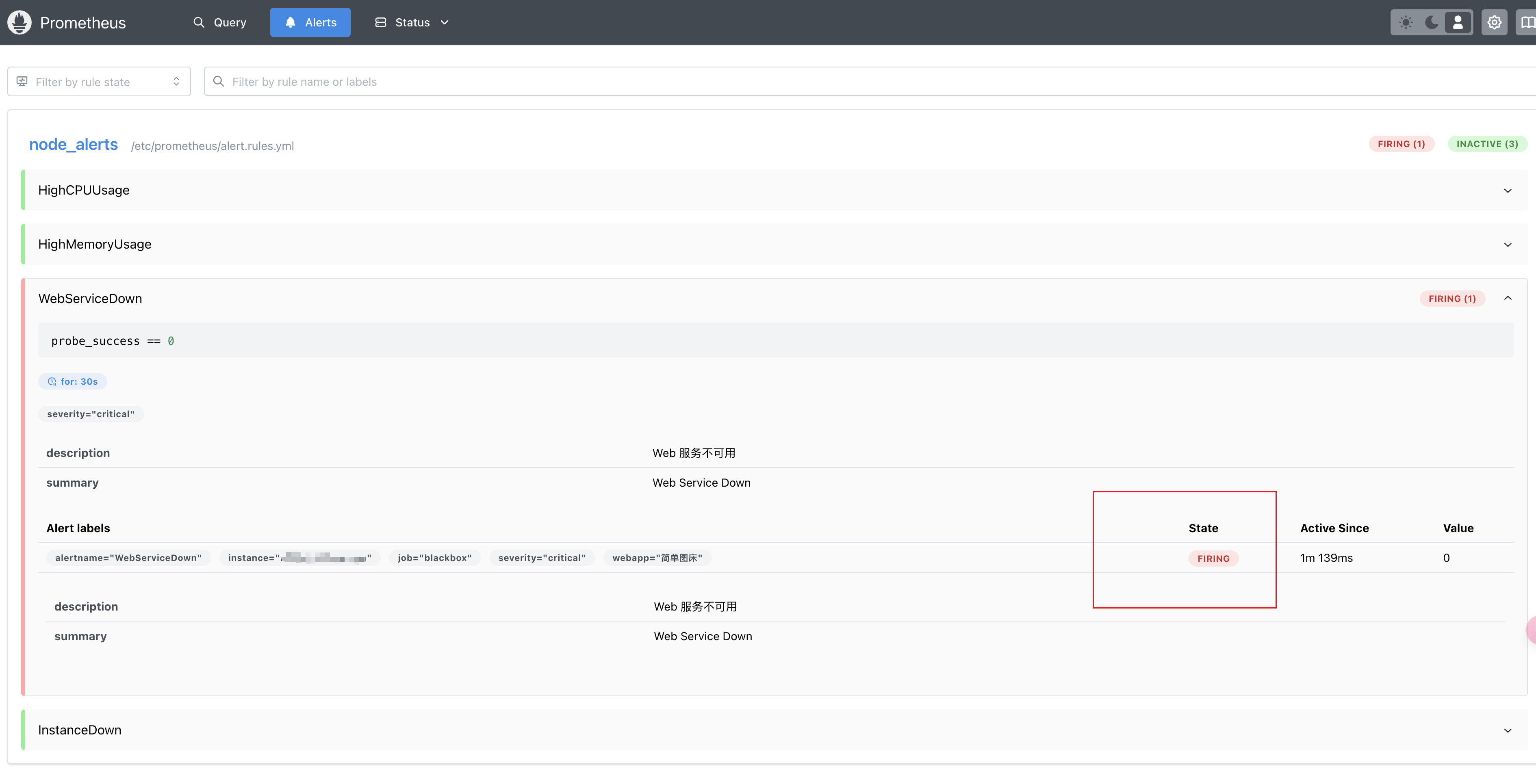
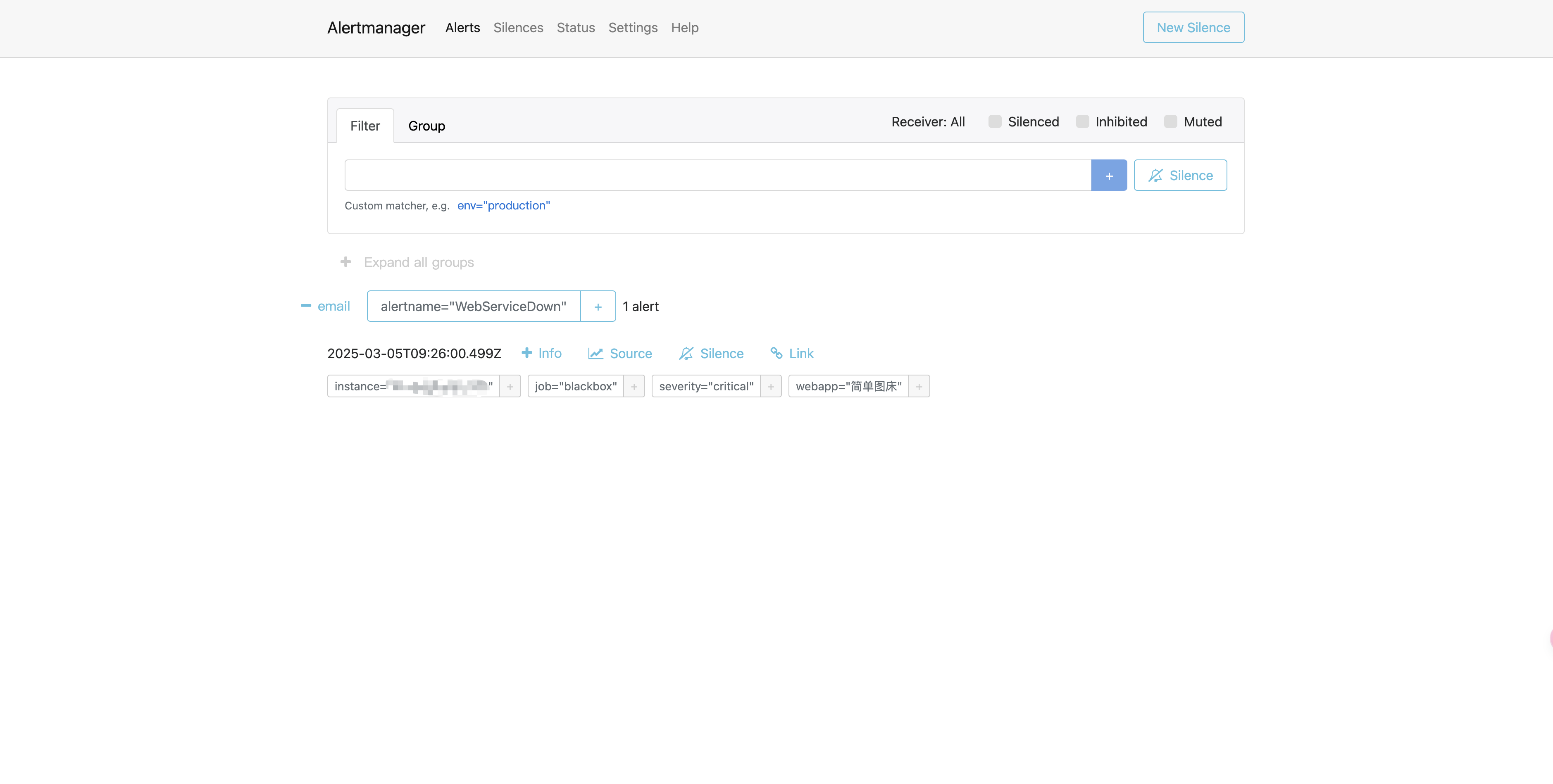
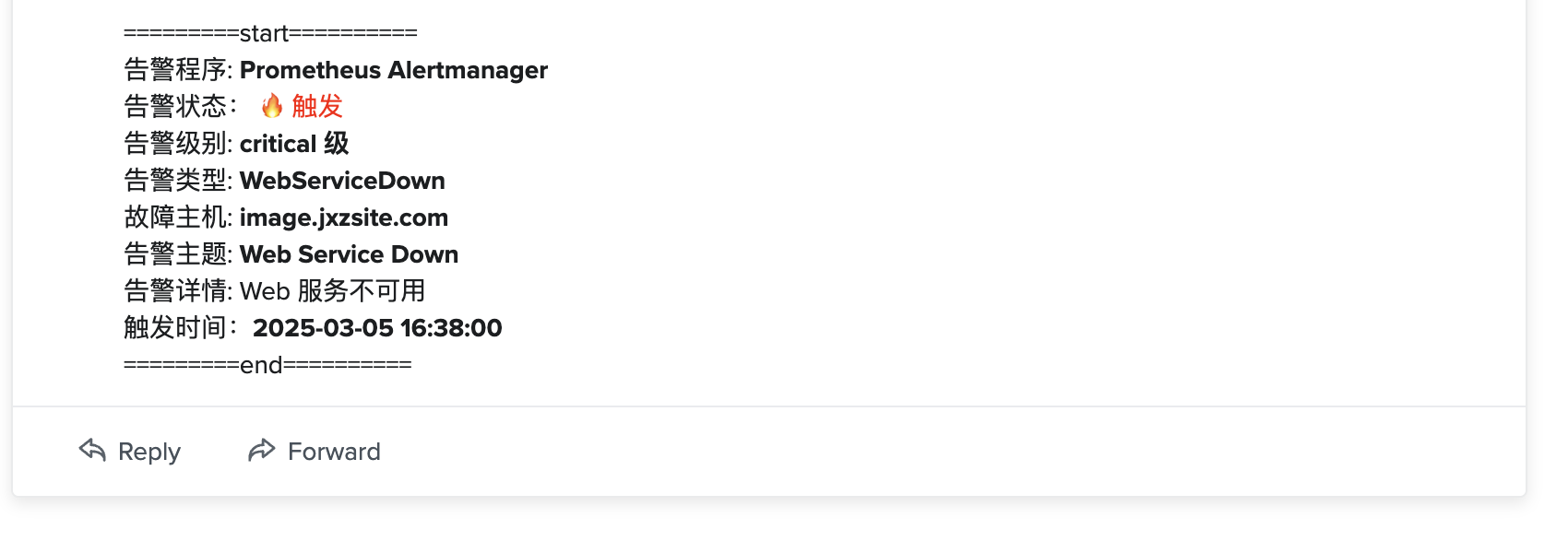
查看告警邮件
总结
通过 Docker Compose,我们快速部署了 Prometheus、Grafana 和 Alertmanager,实现了服务器和 Web 应用的监控与告警。这种方案具有以下优势:
快速部署:使用 Docker Compose 一键启动所有服务。
灵活扩展:可以轻松添加新的监控目标或告警规则。
可视化强大:Grafana 提供了丰富的图表和仪表盘功能。
希望本文能帮助你构建一个高效的监控系统!如果有任何问题,欢迎在评论区讨论。
Happy monitoring!